Why you should use AutoNLU¶
Simple API Easy to use API that just works. Designed for developers, engineers and data scientists to achieve the most in a few simple lines of code. As much automation as possible and as flexible as needed.
Always Up-to-Date in NLP NLP is the fastest moving field in AI. With AutoNLU you don’t have to worry about the latest research to get state-of-the-art results - this is on us! You benefit from advances in the field simply by using the latest version of AutoNLU.
Extensively Tested We use our extensive database of industry datasets to test AutoNLU and ensure it produces high-quality results for a broad set of use cases.
Deep Learning First AutoNLU makes state-of-the-art deep learning in NLP accessible for everyone without having to worry about the complexities of dealing with modern deep learning algorithms.
Plug and Play In two lines of code you can instantly use trained task models to predict your data and get results, e.g. by connecting to our Model Library.
Interoperability AutoNLU, DeepOpinion Studio and other DeepOpinion products are fully interoperable and models can be easily exchanged between the platforms.
Easy interoperability with open source NLP solutions like Huggingface Transformers. E.g. all Huggingface Transformer models can be used as language models in AutoNLU (e.g. for support of a wide range of languages)
Performance compared to open source SOTA¶
AutoNLU beats current open source implementations of Transformer models significantly in training speed, as well as accuracy. The graph compares a typical state of the art implementation to solve different tasks, based on HuggingFace Transformers, to our new, proprietary OMI model in AutoNLU. The two systems are compared using multiple complex real-world customer datasets. The score used is a combination of the F1 score and mean absolute error, which, based on our research, best models the human quality assessment on complex datasets. We show the median results of 24 training runs.
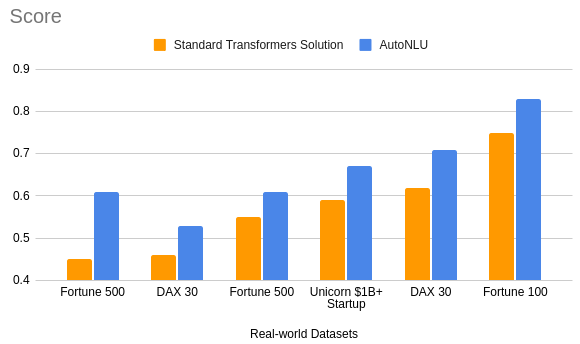
The next graph shows improvements on the training time. On average, the AutoNLU solution is orders of magnitude faster to train, while achieving an 8.5% higher F1 score on average. Most importantly: Because of a very efficient use of the data, the training time is relatively independent of the training dataset size. You can expect to be able to run 10x-20x as many experiments in the same amount of time or directly use automatic hyperparameter optimization and let AutoNLU do the search for the best possible model on its own.
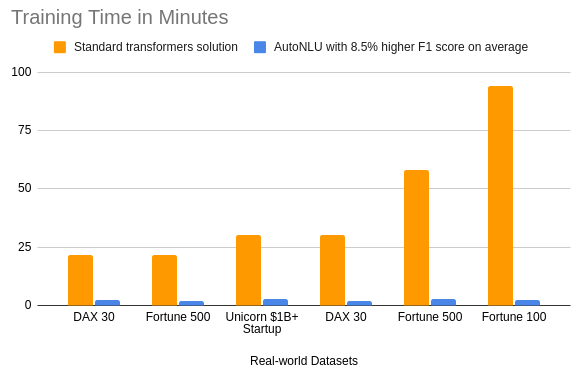
Not only is the training time much faster, but compared to other SOTA solutions based on Transformers, inference is also on average two orders of magnitude faster with AutoNLU. This means we offer a production-ready solution which is suitable for real-world applications.
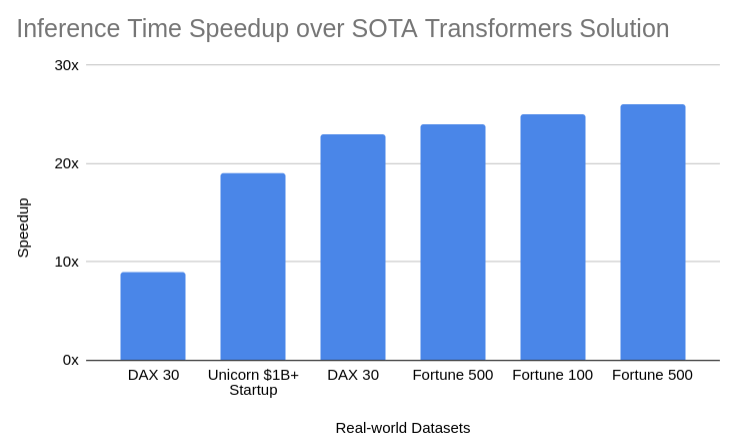
Inference speeds can be increased even further, using advanced technologies like distillation, pruning, mixed floating point precision and quantisation, which are all directly offered by AutoNLU.
Results of AutoNLU on Global Leaderboards¶
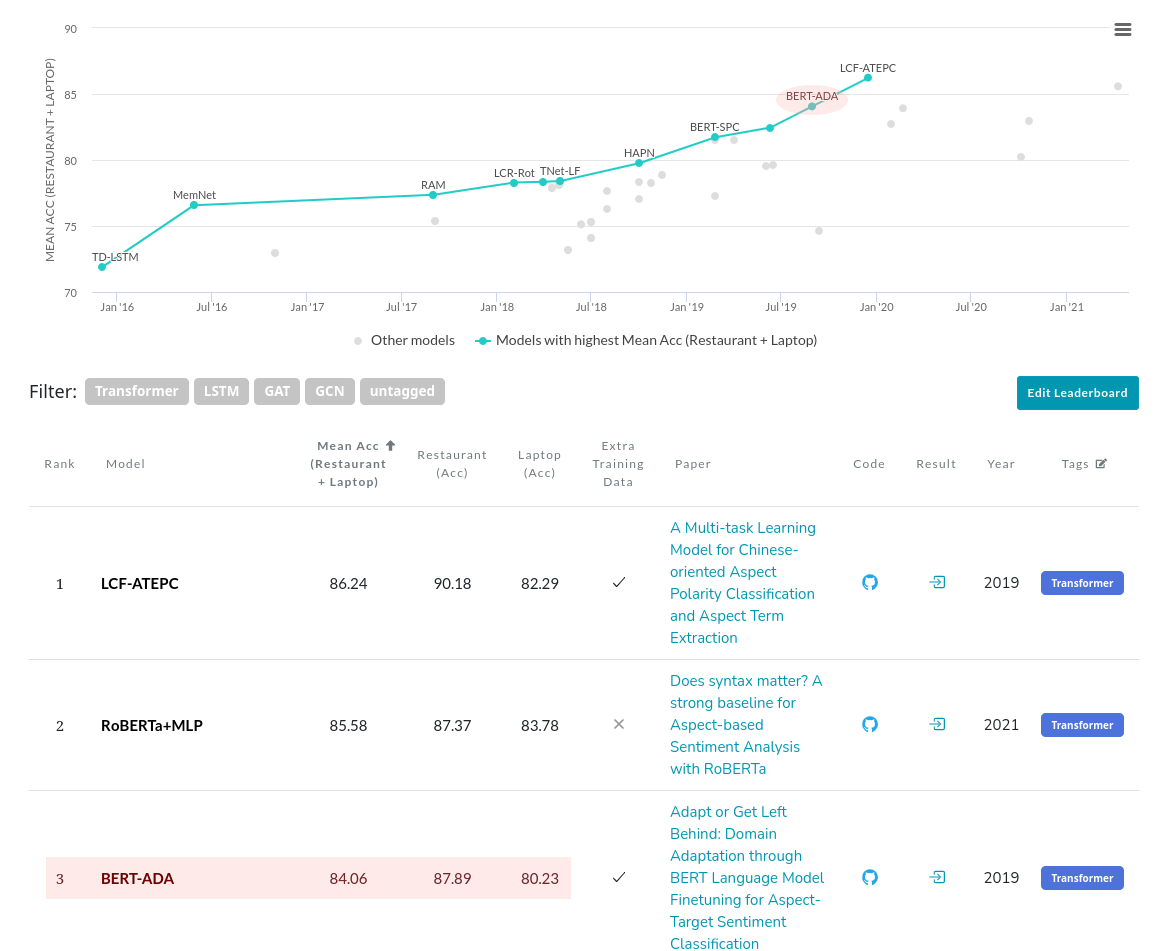
As an example of a complex task we used a reduced version of AutoNLU in 2019 to solve an academic benchmark dataset and published a peer-reviewed paper proving our results - see publications below. We are currently Nr. 3 (and the Nr. 1 company by far) in the SemEval 2014 Task 4 Sub Task 2 (the most popular dataset on the complex task of “Aspect Based Sentiment Analysis”) on Papers with code by Facebook AI Research and were leading the benchmark significantly for some months. Despite officially now being listed as Nr. 3, we still provide the world-leading solution for practical applications.
The current Nr.1 (LCF-ATEPC) needs pre-defined aspect-terms for each sentence during training, which is not practical for real-world applications, since it vastly complicates the labeling of training data.
The current Nr.2 (RoBERTa+MLP) is computationally very expensive and not usable for production systems. In addition, simply replacing BERT with RoBERTa in our implementation (which can be done by changing a single line using AutoNLU), gives results which are comparable, with orders of magnitude faster training and inference times.
Performance on the GLUE Dataset¶
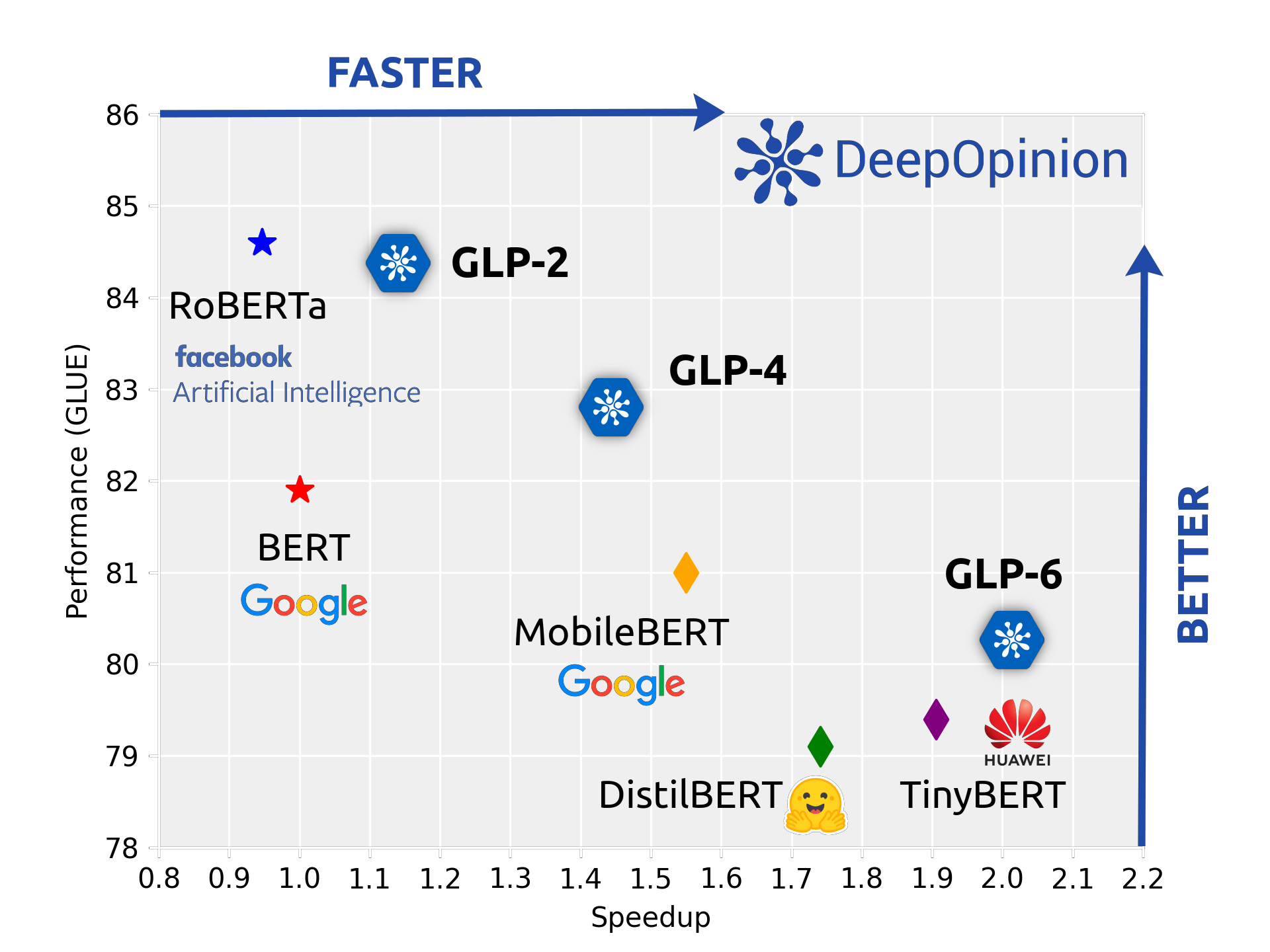
Using our novel pruning approach, we are able to generate language models which offer a much more favourable balance between performance and speedup than existing models. We are able to beat a standard BERT model on the GLUE dataset (one of THE standard datasets for NLP) while being 1.5 times faster in training and inference by pruning a RoBERTa model.
We also vastly outperform Huggingfaces DistilBERT as well as Huaweis TinyBERT in GLUE performance as well as speed and memory consumption.
We Offer More Than Just Transformer Models¶
We agree that sometimes speed is more important then the last half percent of accuracy. To provide maximal inference speed, we also offer language models that are based on a custom CNN architecture. These CNN models can either be trained directly or, our preferred method, used as targets for distilling a bigger Transformer model.
Using distillation, the resulting CNN models perform almost, or sometimes as well, as the original Transformer models, but offer inference speeds that are over 10 times faster compared to our already highly optimized Transformer based models, while also greatly reducing memory consumption.
Fewer Lines of Code and Higher Productivity¶
Using AutoNLU, you can solve real world text classification problems in less than 15 lines of code. The following image compares a tutorial, classifying Google Play Store reviews, using the Huggingface transformers library on the left and the same task solved using AutoNLU on the right.
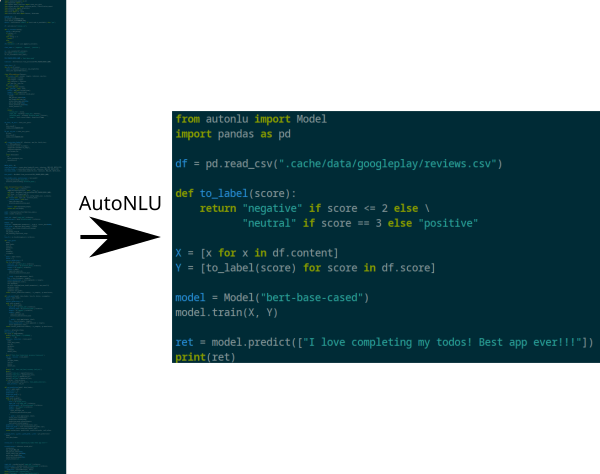
The AutoNLU solution even provides more functionality than the tutorial code on the left (e.g. automatic early stopping, evaluation of the model in regular intervals during training, logging all results to TensorBoard for easy visualization, no need to set hyperparameters, etc.).
AutoNLU itself will usually be only a very small fraction of you code. Once you have the data in the very easy to use format that AutoNLU expects, a state of the art text classification system can be produced in a few lines of code.
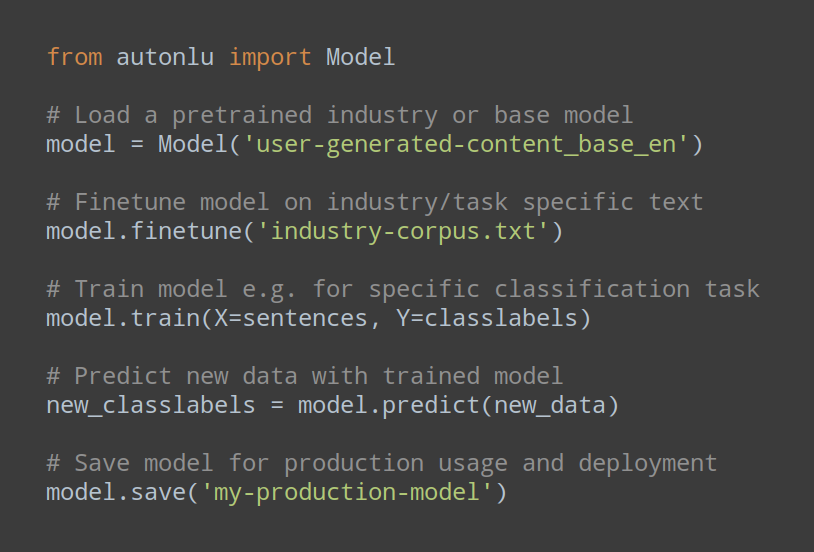
Many of our customers were able to replace hundreds of lines of custom code using for example Hugginface transformers directly with only five lines of AutoNLU calls and still immediatly produced significantly higher performing models.
Direct Integration with DeepOpinion Studio¶
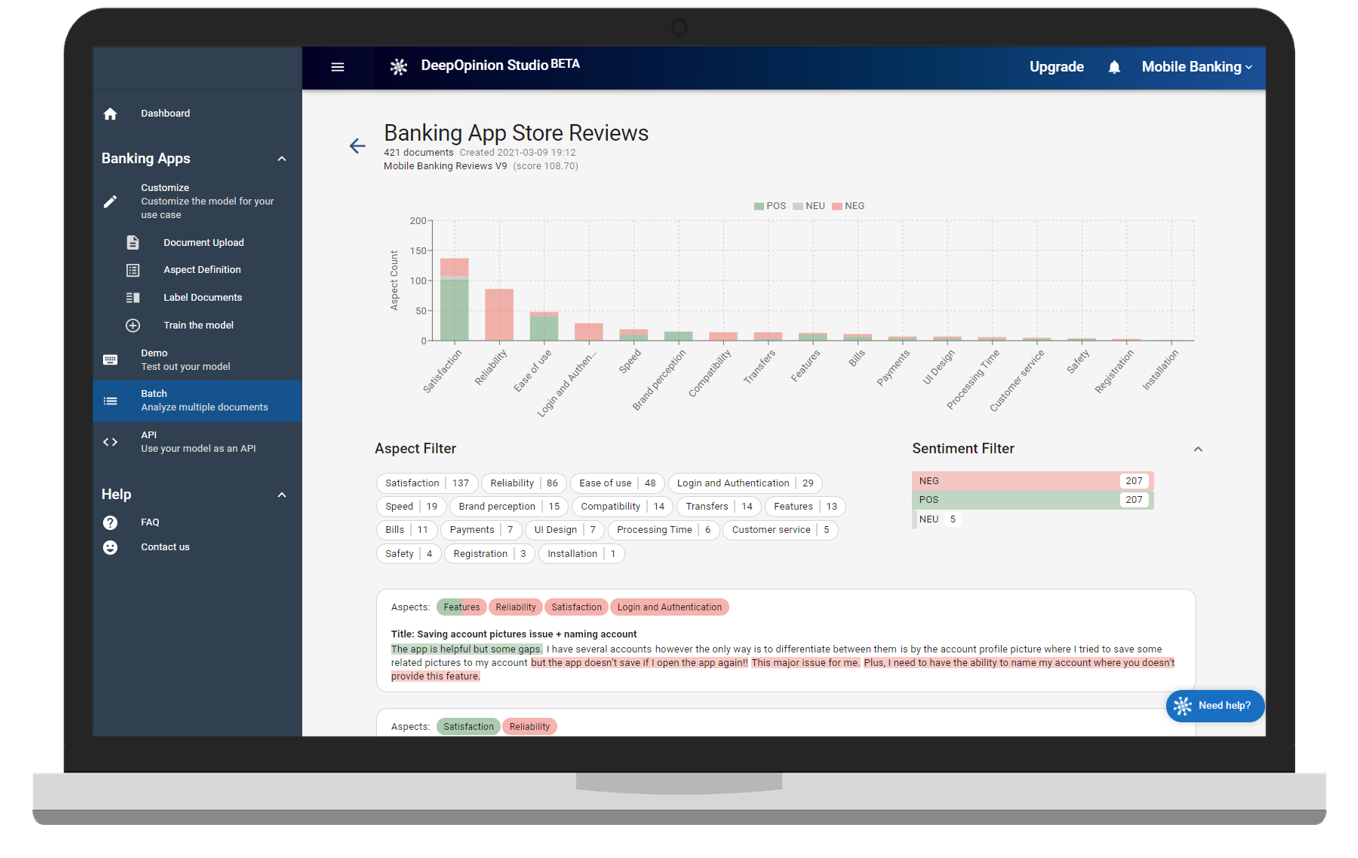
AutoNLU is able to directly interact with DeepOpinion Studio, our no code solution for text classification. Use Studio to comfortably label your data and easily involve domain experts in the labeling process. Pull the training data directly into AutoNLU with a single line of code for model training and optimization.
Create your custom, highly optimized model with AutoNLU and directly upload it to Studio from AutoNLU to run it in the cloud and access it using our RESTful API or for customers to analyze data with it using our comfortable user interface.
We Have a Strong Research Base¶
For AutoNLU, we are not just using existing solutions and algorithms, we conduct a lot of our own research. Some of it has been published … :

Conflicting Bundles: Adapting Architectures Towards the Improved Training of Deep Neural Networks
Auto-tuning of Deep Neural Networks by Conflicting Layer Removal
conflicting_bundle.py—A python module to identify problematic layers in deep neural networks
Greedy Layer Pruning: Decreasing Inference Time of Transformer Models
… some things we keep to our selfs for now:
Our proprietary, highly resource efficient OMI model
A proprietary algorithm for hyper parameter optimization
A distillation procedure with a custom, CNN based model for blazing fast inference speeds, even on CPUs
A novel system for active learning, specifically designed for NLP