Overview of the Software Architecture¶
The information in this document is not needed to use AutoNLU. It describes layers and the states that AutoNLU builds upon and is intended for developers working on AutoNLU. It might nonetheless be interesting to users of AutoNLU as well to understand certain design decisions.
Bottom Up Hierarchy of AutoNLU¶
Huggingface
transformersis used for the low level language modelsautonlu.corecontains our wrapper around language models. The (Classifierclass) implements functionality like splitting data into batches, dynamically adjusting the batch size to react to out of memory errors on the GPU, loading and saving models, calculating losses for training, epoch handling, etc.. It also offers, together with the (CallbackHandlerclass), a system to change the behaviour of the whole system using callback classes (called Modules in AutoNLU)SimpleModelis the first layer that is intended to be used by customers. It is built on top ofClassifierand a set of standard modules that are needed to have a fully functioning system which is able to solve practical problems. It also adds extra functionality like loading a model directly from Studio, performing language model fine tuning, active learning, etc. The SimipleModel also maintains state and ensures that different api calls work together such as train twice, finetune and traine etc. It also ensures that e.g. a CNN model, that does not support finetuning, throws a descriptive exception as this state transition does not exist. The states of a simple model are shown in the image below:
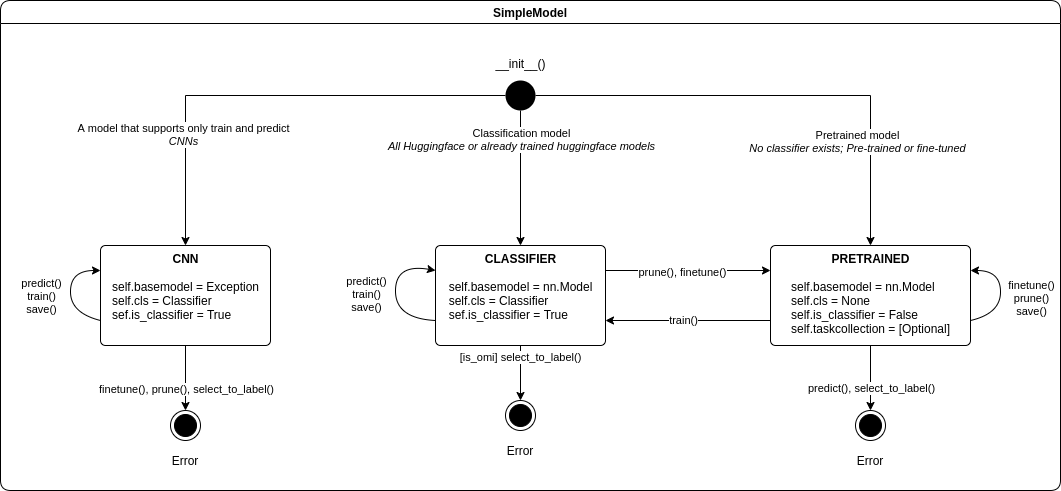
Modelis the main class to be used by customers. It inherits fromSimpleModeland offers easier to use interfaces for the different tasks.DocumentModelis a class that offers a document centric interface. E.g. texts to be analyzed can be given as a hierarchical dictionary and results are returned as the same dictionary with additional annotation-key-value pairs added. Mainly intended as an interface for DO internal software (Studio, ctl-flow)
The Module System¶
Modules¶
A module is a class which inherits from Callback (you can use
autonlu/core/modules/00_moduletemplate.py as a starting point).
Each module implements a number of callback member functions that are
called at specific times during training or inference by
Classifier. e.g. on_epoch_begin will be called if a new epoch
is started, on_model_save is being called before a model is saved
etc.
Quite a big number of modules for all sorts of tasks are already
implemented and can be found in autonlu/core/modules
The Individual Callbacks¶
The individual callbacks have a way to get information about the whole system and also to update the state of the system.
Information can be obtained by specifying arguments with the correct
name. 00_moduletemplate.py mentions which arguments are available.
For example: In a module, we would like to lowecase all sentences from
the current batch before it is being sent to the machine learning
model. We select the callback on_batch_begin, which will be
executed before the batch will be sent through the system. The
corresponding member function from 00_moduletemplate.py looks like
this:
def on_batch_begin(self, **kwargs):
# Updated in internal state: x, y
# Written back: x, y
pass
If we want to have access to the sentences of the batch (x) in our
function, we can just mention it in the signature:
def on_batch_begin(self, x, **kwargs):
# Updated in internal state: x, y
# Written back: x, y
lower_x = [ex.lower() for ex in x]
All arguments that are mentioned in earlier callbacks can also be used
in later callbacks. So we could also mention e.g. modeltype which
was mentioned in before_model_load.
So how do we update which sentences are actually being used for the
next batch by the system? From each callback member function we can
return a dictionary that contains updates to specific values. What
values will be updated is also mentioned as a comment in
00_moduletemplate.py (# Written back: ). In general, arbitrary
dictionaries can be returned, but only the mentioned values will be
updated immediatly for the Classifier. Other modules with the same
callback will get the updated values immediatly though. So our
callback becomes:
def on_batch_begin(self, x, **kwargs):
# Updated in internal state: x, y
# Written back: x, y
return {"x": [ex.lower() for ex in x]}
A callback function can also return arbitrary key/value pairs that are not yet used for anything. This can be used as a loosly coupled way of communication between modules. For example, we could give other modules the information that our module lowered all the sentences by registering a new value:
def on_batch_begin(self, x, **kwargs):
# Updated in internal state: x, y
# Written back: x, y
return {"x": [ex.lower() for ex in x], "was_lowered": True}
Other modules can then request this value and react to it accordingly.
When requesting non-standard information (which might not be there if
a specific module is not currently used) it is generally a good idea
to give a default value of None and check for it. For example,
another module might want to know in on_batch_end (after the batch
has been sent through the model) whether the sentences were lowered,
so we could write:
def on_batch_end(self, was_lowered=None, **kwargs):
# Updated in internal state: x, y, result, nbiterations, nbseensamples
# Written back: x, y, result, nbiterations, nbseensamples
if was_lowered is not None:
print("We just processed lowered sentences")
Value Callbacks¶
We have just been talking about callbacks which are used at specific
points during training/inference/model loading etc. but there is also
a second form of callbacks we have named value callbacks. A value
callback is being called if a specific value has been updated by a
module (even if it was updated to the same value it had before). E.g.
our module might want to react to a change in the batchsize. This can
be achieved by registering functions in the self.val_callbacks
dictionary.
self.val_callbacks["batchsize"] = self.batchsize_change_callback
The Callback Handler¶
- The
CallbackHandlerhas two functions: It holds a global state of the system (in the
statedict)It orchestrates the calling of the callback functions in modules
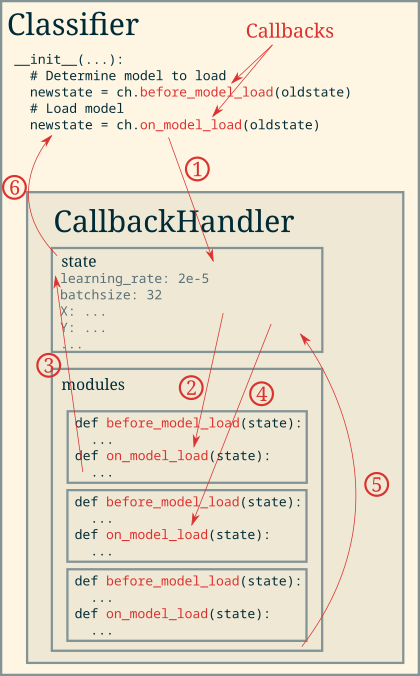
In
Classifier, a certain callback is requested to be executed by the callback handler. The internalstatedict is updated with the information given byClassifierThe callback handler calls the corresponding callback of the first module
The module reports back information which should be updated in/added to the
statedict and the callback handler integrated this informationThe correct callback of each of the modules is called in the appropriate order. Modules are called either in the order they were given when the callback handler was created or in reverse, depending on the specific callback. Generally, callbacks which are executed before sending information through the machine learning model are called in order and callbacks that are called after are called in reverse order.
The returned information of the last module is integrated into the
statedictThe new state is being returned to the
Classifierwhich updates internal variables.
In practice, the calles in Classifier look like this. self.ch
is the callback handler. Values that should be updated in the internal
state dict are passed as named arguments to the callback. The
updated values are returned in the same order as a tuple.
In practice, the calles in Classifier look like this:
# ############# On Model Load #############
self.model, self.device, self.fp16 = self.ch.on_model_load(
model=self.model, device=self.device, fp16=self.fp16)
# ##############################################
self.ch is the callback handler. Values that should be updated in
the internal state dict are passed as named arguments to the
callback. The updated values are returned in the same order as a
tuple.
Although only three values are being passed into the callback, the
callbacks of the modules still can request all information that is in
the state dict
Advantage of this architecture¶
Most of the functionality of AutoNLU is implemented in such modules,
even the actual training step (calculating the gradient and updating
the weights using an optimizer) are implemented in modules and are not
part of AutoNLU or the Classifier itself. This makes it very easy
to replace components. Other examples of modules:
Sorting sentences by token length for faster inference
Evaluating of the model in regular intervals
Keeping the best model and reloading it after training is finished
Tensorboard logging
Encryption/Decryption of models on save/load
…
This architecture makes the core of AutoNLU extremely flexible and allows new ideas and research results to be implemented without having to change and increase the complexity of the core.
This keeps the actual system that is used for production very clean, even if hundrets of different pre-processing stepts, data augmentation schemes, training improvements, …, are implemented and can be used (also in combination) at a moments notice.